
End-to-end Pipeline with KFServing
All tutorials in Jupyter Notebook format are available for download. You can either download them to a local computer and upload to the running Jupyter Notebook or run the following command from a Jupyter Notebook Terminal running in your Kaptain installation:
curl -L https://downloads.d2iq.com/kaptain/d2iq-tutorials-2.2.0.tar.gz | tar xzThese notebook tutorials have been built for and tested on D2iQ's Kaptain. Without the requisite Kubernetes operators and custom Docker images, these notebooks will likely not work.
Kubeflow Pipelines: from Training to Serving
Introduction
With Kubeflow Pipelines you can build entire workflows that automate the steps involved in going from training a machine learning model to actually serving an optimized version of it. These steps can be triggered automatically by a CI/CD workflow or on demand from a command line or notebook.
Kubeflow Pipelines (kfp) comes with a user interface for managing and tracking experiments, jobs, and runs. A pipeline is a description of a machine learning workflow, replete with all inputs and outputs. In Kubeflow Pipelines, an experiment is a workspace where you can experiment with different configurations of your pipelines. Experiments are a way to organize runs of jobs into logical groups. A run is simply a single execution (instance) of a pipeline. Kubeflow Pipelines also supports recurring runs, which is a repeatable run of a pipeline. Based on a so-called run trigger an instance of a pipeline with its run configuration is periodically started. As of now, run triggers are time-based (i.e., not event-based).
In the UI, there is a pictorial representation of the runtime execution of a pipeline. This graph consists of one or more steps (i.e. nodes). Each step, the directed edges (arrows) show the parent/child relationship: A → B means that B depends on A; B cannot start until A has successfully completed.
A component performs a single step in the pipeline (e.g. data ingestion, data preprocessing, data transformation, model training, hyperparameter tuning). It is analogous to a function: it has a name, (metadata) parameters and return values (interface), and a body (implementation). It must therefore be self-contained. Each component must be packaged as a Docker image. Please note that components are independently executed: they do not share the same process and cannot share in-memory data.
What You Will Learn
This notebook trains a simple (MNIST) model in TensorFlow and serves it with KFServing, which is a serverless inference server. What this means is that you do not have to worry about which machines it runs on, networking, autoscaling, health checks, and what have you. Instead, you can focus on what matters to you: the model and a REST API you can call for predictions. If you are familiar with Kubernetes, you can even do out-of-the-box canary deployments, in which a percentage of traffic is directed to the ‘canary (in the coal mine)’ with the latest model to ensure it functions properly before completely rolling out any (potentially problematic) updates.
If you prefer to use a more sophisticated model or a PyTorch-based one, you can check out the relevant notebooks: MNIST with TensorFlow or MNIST with PyTorch.
KFServing reads the model file from MinIO, an open-source S3-compliant object storage tool, which is already included with your Kubeflow installation.
MinIO holds the input data set for the pipeline. This way it can run without a connection to the Internet.
What You Need
This notebook.
Prerequisites
Install the MinIO Client. Refer to the quickstart guide for instructions.
Ensure Kubeflow Pipelines is available:
CODE%%sh pip show kfp
How to Configure Credentials
In order for KFServing to access MinIO, the credentials must be added to the default service account.
NOTE: KFServing is imported as a pipeline component (ContainerOp) in this notebook. Consequently, it does not allow configuration of custom service accounts.
%%writefile minio_secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: minio-s3-secret
annotations:
serving.kserve.io/s3-endpoint: kaptain-minio.kubeflow
serving.kserve.io/s3-usehttps: "0" # Default: 1. Must be 0 when testing with MinIO!
type: Opaque
data:
awsAccessKeyID: bWluaW8=
awsSecretAccessKey: bWluaW8xMjM=
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: default
secrets:
- name: minio-s3-secretWriting minio_secret.yaml%%sh
kubectl apply -f minio_secret.yamlsecret/minio-s3-secret created
serviceaccount/default configuredCopy input data set into MinIO using its CLI
First, you will need to install the MinIO Command Line Client mc. Refer to the quickstart guide for instructions.
%%sh
set -o errexit
curl https://dl.min.io/client/mc/release/linux-amd64/mc --create-dirs -o ${HOME}/mc
chmod +x ${HOME}/mcNext, configure credentials for mc.
%%sh
set -o errexit
minio_accesskey=$(kubectl get secret minio-creds-secret -o jsonpath="{.data.accesskey}" | base64 --decode)
minio_secretkey=$(kubectl get secret minio-creds-secret -o jsonpath="{.data.secretkey}" | base64 --decode)
./mc --no-color alias set minio http://kaptain-minio.kubeflow ${minio_accesskey} ${minio_secretkey}mc: Configuration written to `/home/kubeflow/.mc/config.json`. Please update your access credentials.
mc: Successfully created `/home/kubeflow/.mc/share`.
mc: Initialized share uploads `/home/kubeflow/.mc/share/uploads.json` file.
mc: Initialized share downloads `/home/kubeflow/.mc/share/downloads.json` file.
Added `minio` successfully.Use it to create a bucket, upload the dataset to it, and set access policy so that the pipeline can download it from MinIO. You may want to change the default bucket names used by this tutorial, since MinIO buckets are global resources shared between all cluster users.
INPUT_BUCKET = "pipelines-tutorial-data"
EXPORT_BUCKET = "pipelines-tutorial-model"%env INPUT_BUCKET $INPUT_BUCKET%%sh
./mc --no-color mb "minio/${INPUT_BUCKET}"Bucket created successfully `minio/tutorial`.%%sh
set -o errexit
tar --dereference -czf datasets.tar.gz ./datasets
./mc --no-color cp datasets.tar.gz "minio/${INPUT_BUCKET}/datasets.tar.gz"
./mc anonymous --no-color policy set download "minio/${INPUT_BUCKET}"...ts.tar.gz: 16.14 MiB / 16.14 MiB |=========================| 141.66 MiB/s 0sAccess permission for `minio/tutorial` is set to `download`How to Implement Kubeflow Pipelines Components
Components are self-contained pieces of code: Python functions.
The function must be completely self-contained. No code (incl. imports) can be defined outside of the body itself. All imports must be included in the function body itself! Imported packages must be available in the base image.
Why? Because each component will be packaged as a Docker image. The base image must therefore contain all dependencies. Any dependencies you install manually in the notebook are invisible to the Python function once it is inside the image. The function itself becomes the entrypoint of the image, which is why all auxiliary functions must be defined inside the function. That does cause some unfortunate duplication, but it also means you do not have to worry about the mechanism of packaging.
For the pipeline, define four components:
Download the MNIST data set
Train the TensorFlow model
Evaluate the trained model
Export the trained model
Serve the trained model
You will also need the current Kubernetes namespace, which you can retrieve using the following code:
from typing import NamedTuple
import kfp
import kfp.components as components
import kfp.dsl as dsl
from kfp.components import InputPath, OutputPath
with open('/var/run/secrets/kubernetes.io/serviceaccount/namespace', 'r') as f:
NAMESPACE = f.readline()
%env NAMESPACE $NAMESPACEFunction arguments specified with InputPath and OutputPath are the key to defining dependencies. For now, it suffices to think of them as the input and output of each step. How to define dependencies is explained in the next section.
Component 1: Download the MNIST Data Set
def download_dataset(data_dir: OutputPath(str), input_bucket: str):
"""Download the MNIST data set to the Kubeflow Pipelines volume to share it among all steps"""
import urllib.request
import tarfile
import os
if not os.path.exists(data_dir):
os.makedirs(data_dir)
url = f"http://kaptain-minio.kubeflow/{input_bucket}/datasets.tar.gz"
stream = urllib.request.urlopen(url)
tar = tarfile.open(fileobj=stream, mode="r|gz")
tar.extractall(path=data_dir)Component 2: Train the Model
For both the training and evaluation, divide the integer-valued pixel values by 255 to scale all values into the [0, 1] (floating-point) range. This function must be copied into both component functions (cf. normalize_image).
If you wish to learn more about the model code, please have a look at the MNIST with TensorFlow notebook.
def train_model(data_dir: InputPath(str), model_dir: OutputPath(str)):
"""Trains a single-layer CNN for 5 epochs using a pre-downloaded dataset.
Once trained, the model is persisted to `model_dir`."""
import os
import tensorflow as tf
import tensorflow_datasets as tfds
def normalize_image(image, label):
"""Normalizes images: `uint8` -> `float32`"""
return tf.cast(image, tf.float32) / 255.0, label
model = tf.keras.models.Sequential(
[
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax"),
]
)
model.compile(
loss="sparse_categorical_crossentropy",
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=["accuracy"],
)
print(model.summary())
ds_train, ds_info = tfds.load(
"mnist",
split="train",
shuffle_files=True,
as_supervised=True,
with_info=True,
download=False,
data_dir=f"{data_dir}/datasets",
)
# See: https://www.tensorflow.org/datasets/keras_example#build_training_pipeline
ds_train = ds_train.map(
normalize_image, num_parallel_calls=tf.data.experimental.AUTOTUNE
)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(ds_info.splits["train"].num_examples)
ds_train = ds_train.batch(128)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
model.fit(
ds_train,
epochs=5,
)
model.save(model_dir)
print(f"Model saved {model_dir}")
print(os.listdir(model_dir))Component 3: Evaluate the Model
Evaluate the model with the following Python function. The metrics metadata (loss and accuracy) is available to the Kubeflow Pipelines UI. All metadata can automatically be visualized with output viewer(s).
def evaluate_model(
data_dir: InputPath(str), model_dir: InputPath(str), metrics_path: OutputPath(str)
) -> NamedTuple("EvaluationOutput", [("mlpipeline_metrics", "Metrics")]):
"""Loads a saved model from file and uses a pre-downloaded dataset for evaluation.
Model metrics are persisted to `/mlpipeline-metrics.json` for Kubeflow Pipelines
metadata."""
import json
import tensorflow as tf
import tensorflow_datasets as tfds
from collections import namedtuple
def normalize_image(image, label):
return tf.cast(image, tf.float32) / 255.0, label
ds_test, ds_info = tfds.load(
"mnist",
split="test",
shuffle_files=True,
as_supervised=True,
with_info=True,
download=False,
data_dir=f"{data_dir}/datasets",
)
# See: https://www.tensorflow.org/datasets/keras_example#build_training_pipeline
ds_test = ds_test.map(
normalize_image, num_parallel_calls=tf.data.experimental.AUTOTUNE
)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
model = tf.keras.models.load_model(model_dir)
(loss, accuracy) = model.evaluate(ds_test)
metrics = {
"metrics": [
{"name": "loss", "numberValue": str(loss), "format": "PERCENTAGE"},
{"name": "accuracy", "numberValue": str(accuracy), "format": "PERCENTAGE"},
]
}
with open(metrics_path, "w") as f:
json.dump(metrics, f)
out_tuple = namedtuple("EvaluationOutput", ["mlpipeline_metrics"])
return out_tuple(json.dumps(metrics))Component 4: Export the Model
def export_model(
model_dir: InputPath(str),
metrics: InputPath(str),
export_bucket: str,
model_name: str,
model_version: int,
):
import os
import boto3
from botocore.client import Config
s3 = boto3.client(
"s3",
endpoint_url="http://kaptain-minio.kubeflow",
aws_access_key_id="minio",
aws_secret_access_key="minio123",
config=Config(signature_version="s3v4"),
)
# Create export bucket if it does not yet exist
response = s3.list_buckets()
export_bucket_exists = False
for bucket in response["Buckets"]:
if bucket["Name"] == export_bucket:
export_bucket_exists = True
if not export_bucket_exists:
s3.create_bucket(ACL="public-read-write", Bucket=export_bucket)
# Save model files to S3
for root, dirs, files in os.walk(model_dir):
for filename in files:
local_path = os.path.join(root, filename)
s3_path = os.path.relpath(local_path, model_dir)
s3.upload_file(
local_path,
export_bucket,
f"{model_name}/{model_version}/{s3_path}",
ExtraArgs={"ACL": "public-read"},
)
response = s3.list_objects(Bucket=export_bucket)
print(f"All objects in {export_bucket}:")
for file in response["Contents"]:
print("{}/{}".format(export_bucket, file["Key"]))Component 5: Serve the Model
Kubeflow Pipelines comes with a set of pre-defined components which can be imported from GitHub repo and reused across the pipelines without the need to define it every time. A copy of the KFServing component is included with the tutorial to make it work in an air-gapped environment. Here’s what the import looks like:
kfserving = components.load_component_from_file("kfserving-component.yaml")How to Combine the Components into a Pipeline
Note that up to this point you have not yet used the Kubeflow Pipelines SDK!
With the four components (i.e. self-contained functions) defined, wire up the dependencies with Kubeflow Pipelines.
The call components.func_to_container_op(f, base_image=img)(*args) has the following ingredients:
fis the Python function that defines a componentimgis the base (Docker) image used to package the function*argslists the arguments tof
What the *args mean is best explained by going forward through the graph:
downloadOpis the first step and has no dependencies; it therefore has noInputPath. Its output (i.e.,OutputPath) is stored indata_dir.trainOpneeds the data downloaded fromdownloadOpand its signature listsdata_dir(input) andmodel_dir(output). It depends ondownloadOp.output(i.e., the previous step’s output) and stores its own outputs inmodel_dir, which can be used by another step.downloadOpis the parent oftrainOp, as required.evaluateOp's function takes three arguments:data_dir(i.e.,downloadOp.output),model_dir(i.e.,trainOp.output), andmetrics_path, which is where the function stores its evaluation metrics. That way,evaluateOpcan only run after the successful completion of bothdownloadOpandtrainOp.exportOpruns the functionexport_model, which accepts five parameters:model_dir,metrics,export_bucket,model_name, andmodel_version. From where do you get themodel_dir? It is nothing buttrainOp.output. Similarly,metricsisevaluateOp.output. The remaining three arguments are regular Python arguments that are static for the pipeline: they do not depend on any step’s output being available. Hence, they are defined without usingInputPath.kfservingOpis loaded from the external component and its order of execution should be specified explicitly by usingkfservingOp.after(evaluateOp)function which assignsexportOpas a parent. Just in case it isn’t obvious: this will build the Docker images for you. Each image is based onBASE_IMAGEand includes the Python functions as executable files. Each component can use a different base image though. This may come in handy if you want to have reusable components for automatic data or model analysis (e.g. to investigate bias).
Remember when we said all dependencies have to be included in the base image? Well, that was not quite accurate. It is a good idea to have everything included and tested before you define and use your pipeline components to make sure that there are no dependency conflicts. You can add packages (packages_to_install) and additional code to execute before the function code (extra_code) though.
For GPU support, please add the “-gpu” suffix to the base image.
BASE_IMAGE = "mesosphere/kubeflow:2.2.0-tensorflow-2.9.1"def train_and_serve(
input_bucket: str,
data_dir: str,
model_dir: str,
export_bucket: str,
model_name: str,
model_version: int,
):
downloadOp = components.func_to_container_op(
download_dataset, base_image=BASE_IMAGE
)(input_bucket)
downloadOp.set_retry(5).set_cpu_limit("100m").set_memory_limit("256M")
trainOp = (
components.func_to_container_op(train_model, base_image=BASE_IMAGE)(
downloadOp.output
)
.set_cpu_limit("1")
.set_memory_limit("1G")
)
evaluateOp = (
components.func_to_container_op(evaluate_model, base_image=BASE_IMAGE)(
downloadOp.output, trainOp.output
)
.set_cpu_limit("500m")
.set_memory_limit("500M")
)
# To make GPU available for any of the pipeline steps, specify the required amount via `set_gpu_limit(<number of GPUs>)`.
# It is also important to make sure that the image used to run the step has GPU drivers installed. Here's an example
# of such a heuristic which enables GPUs for the training and evaluation steps if the image tag has a specific prefix.
if BASE_IMAGE.endswith("-gpu"):
trainOp.set_gpu_limit(1).set_memory_limit("3G")
evaluateOp.set_gpu_limit(1).set_memory_limit("3G")
exportOp = (
components.func_to_container_op(export_model, base_image=BASE_IMAGE)(
trainOp.output, evaluateOp.output, export_bucket, model_name, model_version
)
.set_cpu_limit("100m")
.set_memory_limit("256M")
)
kfservingOp = kfserving(
action="apply",
model_uri=f"s3://{export_bucket}/{model_name}",
model_name="mnist",
namespace=NAMESPACE,
framework="tensorflow",
watch_timeout="300",
)
kfservingOp.after(exportOp)Is that it? Not quite!
That leaves pipeline itself for you to define. The train_and_serve function defines dependencies but you must use the Kubeflow Pipelines domain-specific language (DSL) to register the pipeline with its four components:
# See: https://github.com/kubeflow/kfserving/blob/master/docs/DEVELOPER_GUIDE.md#troubleshooting
def op_transformer(op):
op.add_pod_annotation(name="sidecar.istio.io/inject", value="false")
return op
@dsl.pipeline(
name="End-to-End MNIST Pipeline",
description="A sample pipeline to demonstrate multi-step model training, evaluation, export, and serving",
)
def mnist_pipeline(
input_bucket: str = "tutorial",
model_dir: str = "/train/model",
data_dir: str = "/train/data",
export_bucket: str = "mnist",
model_name: str = "mnist",
model_version: int = 1,
):
train_and_serve(
input_bucket=input_bucket,
data_dir=data_dir,
model_dir=model_dir,
export_bucket=export_bucket,
model_name=model_name,
model_version=model_version,
)
dsl.get_pipeline_conf().add_op_transformer(op_transformer)
# TTL for the workflow to persist after completion (1 hour)
dsl.get_pipeline_conf().set_ttl_seconds_after_finished(60 * 60)Submit the pipeline directly from the notebook:
pipeline_func = mnist_pipeline
run_name = pipeline_func.__name__ + " run"
experiment_name = "End-to-End MNIST Pipeline-" + NAMESPACE
arguments = {
"input_bucket": INPUT_BUCKET,
"model_dir": "/train/model",
"data_dir": "/train/data",
"export_bucket": EXPORT_BUCKET,
"model_name": "mnist",
"model_version": "1",
}
client = kfp.Client()
run_result = client.create_run_from_pipeline_func(
pipeline_func,
experiment_name=experiment_name,
run_name=run_name,
arguments=arguments,
namespace=NAMESPACE
)The pipeline is now running. Wait for it to complete successfully. In the meantime you can use the links above to see the pipelines UI.
completed_run = run_result.wait_for_run_completion(timeout=900)
assert (
completed_run.run.status == "Succeeded" and completed_run.run.error is None
), f"{completed_run.run.status}, {completed_run.run.error}"[I 200930 08:38:30 _client:601] Waiting for the job to complete...The graph will look like this:
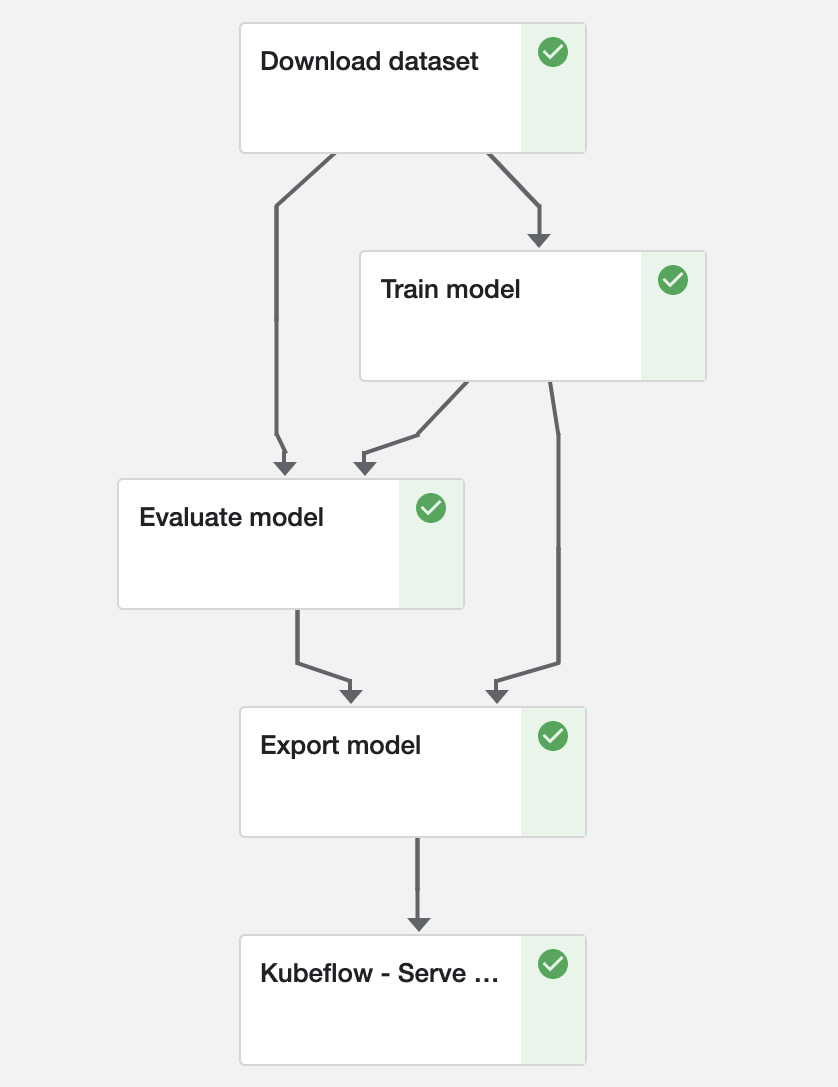
If there are any issues with the pipeline definition, this is where they would flare up. Until you submit it, you will not know if your pipeline definition is correct.
We have so far claimed that Kubeflow Pipelines is for automation of multi-step (ad hoc) workflows and usage in CI/CD. You may have wondered why that is. After all, it is possible to set up recurring runs of pipelines. The reason is that these pipeline steps are one-offs. Even though you can parameterize each step, including the ones that kick off an entire pipeline, there is no orchestration of workflows. Stated differently, if a step fails, there is no mechanism for automatic retries. Nor is there any support for marking success: if the step is scheduled to run again, it will run again, whether or not the previous execution was successful, obviating any subsequent runs (except in cases where it may be warranted). Kubeflow Pipelines allows retries but it is not configurable out of the box. If you want Airflow- or Luigi-like behaviour for dependency management of workflows, Kubeflow Pipelines is not the tool.
How to Predict with the Inference Server
The simplest way to check that the inference server is up and running is to check it with curl ( pre-installed on the cluster).
To do so, define a few helper functions for plotting and displaying images:
import matplotlib.pyplot as plt
def display_image(x_test, image_index):
plt.imshow(x_test[image_index].reshape(28, 28), cmap="binary")
def predict_number(model, x_test, image_index):
pred = model.predict(x_test[image_index : image_index + 1])
print(pred.argmax())import numpy as np
with np.load("datasets/mnist.npz", allow_pickle=True) as f:
x_test = (
f["x_test"] / 255.0
) # Transform the data in the same way as before!
image_index = 1005
display_image(x_test, image_index)

The inference server expects a JSON payload:
import codecs, json
tf_serving_req = {"instances": x_test[image_index : image_index + 1].tolist()}
with open("input.json", "w") as json_file:
json.dump(tf_serving_req, json_file)
%%sh
set -o errexit
model="mnist"
url="http://${model}.${NAMESPACE}.svc.cluster.local/v1/models/${model}:predict"
curl --fail -L "${url}" -d@input.json -o output.json % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 6028 100 186 100 5842 13285 407k --:--:-- --:--:-- --:--:-- 420k%%sh
jq -M . output.json{
"predictions": [
[
9.83620794e-08,
7.66133439e-07,
3.47602878e-07,
0.000236162232,
0.000462783792,
1.87035937e-06,
1.21420118e-08,
6.01991742e-05,
1.12252283e-05,
0.99922657
]
]
}The probabilities for each class (0-9) are shown in the predictions response. The model believes the image shows a “9”, which indeed it does!
%%sh
jq -M --exit-status '.predictions[0] | indices(max)[0] == 9' output.jsontrueFor more details on the URL, please check out this example.
This tutorial includes code from the MinIO Project (“MinIO”), which is © 2014-2022 MinIO, Inc. MinIO is made available subject to the terms and conditions of the Apache Software Foundation, Apache License V2.0. The complete source code for the version of MinIO packaged with Kaptain 2.2.0 is available at this URL:
For a full list of attributed 3rd party software, see http://d2iq.com/legal/3rd