
Rook Ceph Configuration
This page contains information about configuring Rook Ceph in your DKP Environment.
The Ceph instance installed by DKP is intended only for use by the logging stack and velero platform applications.
If you have an instance of Ceph that is managed outside of the DKP lifecycle, see Bring Your Own Storage to DKP Clusters.
Components of a Rook Ceph Cluster
Ceph supports creating clusters in different modes as listed in CephCluster CRD - Rook Ceph Documentation. DKP, specifically is shipped with a PVC Cluster, as documented in PVC Storage Cluster - Rook Ceph Documentation. It is recommended to use the PVC mode to keep the deployment and upgrades simple and agnostic to technicalities with node draining.
Ceph cannot be your CSI Provisioner when installing in PVC mode as Ceph relies on an existing CSI provisioner to bind the PVCs created by it. It is possible to use Ceph as your CSI provisioner, but that is outside the scope of this document. If you have an instance of Ceph that acts as the CSI Provisoner, then it is possible to reuse it for your DKP Storage needs. See BYOS (Bring Your Own Storage) to DKP Clusters for information on reusing existing Ceph.
When you create AppDeployments for rook-ceph and rook-ceph-cluster platform applications results in the deployment of various components as listed in the following diagram:
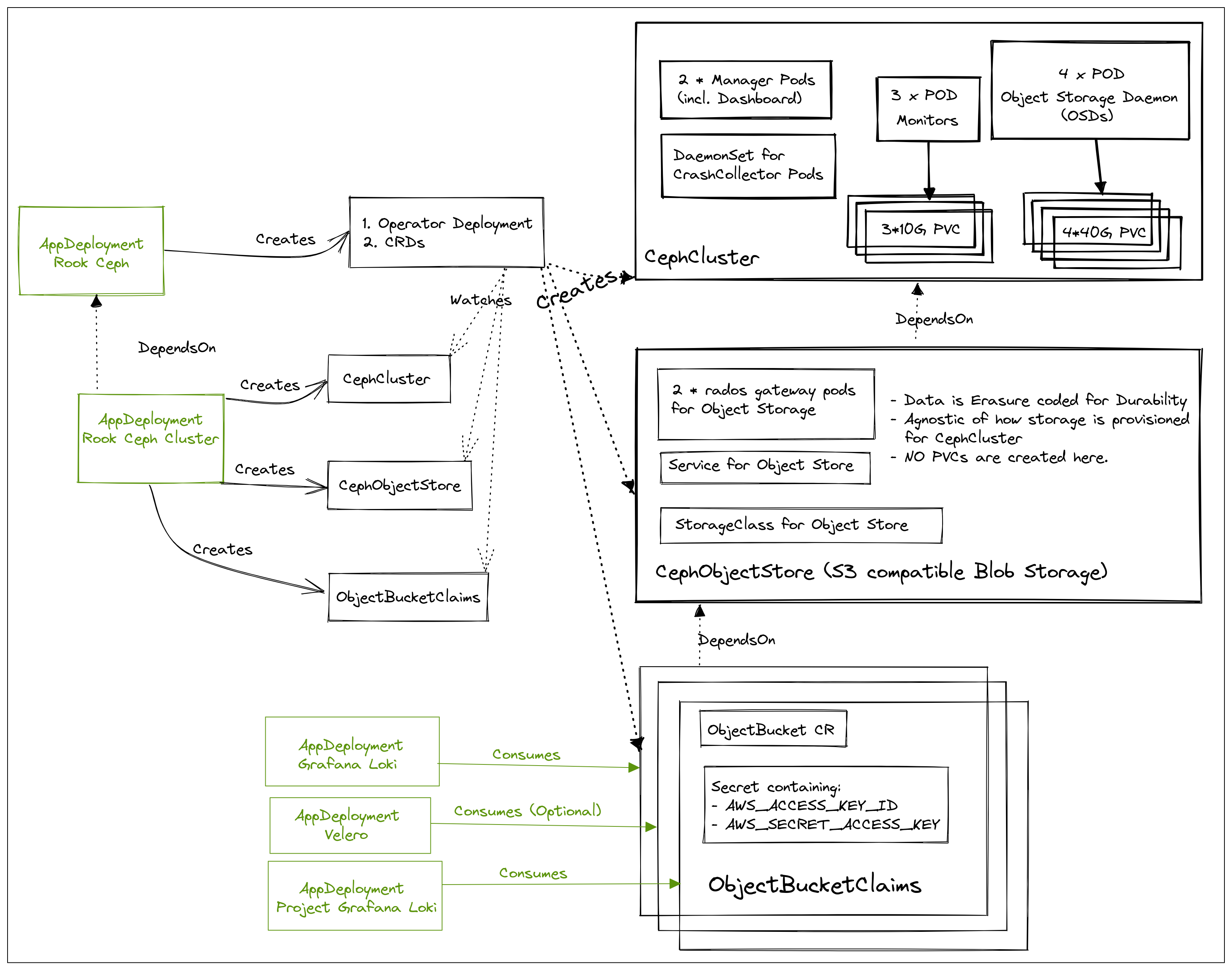
Rook Ceph Cluster Components
Items highlighted in green are user-facing and configurable.
Please refer to Rook Ceph Storage Architecture and Ceph Architecture for an in-depth explanation of the inner workings of the components outlined in the above diagram.
For additional details about the data model, refer to the Rook Ceph Data Model page.
Resource Requirements
The following is a non-exhaustive list of the resource requirements for long running components of Ceph:
Type | Resources | Total |
|---|---|---|
CPUs | 100m x # of mgr instances (default 2) 250m x # of mon instances (default 3) 250m x # of osd instances (default 4) 100m x # of crashcollector instances (Daemonset i.e., # of nodes) 250m x # of rados gateway replicas (default 2) | ~2000m CPU |
Memory | 512Mi x # of mgr instances (default 2) 512Gi x # of mon instances (default 3) 1Gi x # of osd instances (default 4) 500Mi x # of rados gateway replicas (default 2) | ~8Gi Memory |
Disk | 4 x 40Gi PVCs with 3 x 10Gi PVCs with | 190Gi |
Your default StorageClass should support creation of PersistentVolumes that satisfy the PersistentVolumeClaims created by Ceph with volumeMode: Block.
Ceph Storage Configuration
Ceph is highly configurable and can support Replication or Erasure Coding to ensure data durability. DKP is configured to use Erasure Coding for maximum efficiency.
The default configuration creates a CephCluster that creates 4 x PersistentVolumeClaims of 40G each, resulting in 160G of raw storage. Erasure coding ensures durability with k=3 data bits and m=1 parity bits. This gives a storage efficiency of 75% (refer to the primer above for calculation), which means 120G of disk space is available for consumption by services like grafana-loki, project-grafana-loki, and velero.
It is possible to override replication strategy for logging stack (grafana-loki) and velero backups. Refer to the default configmap for the CephObjectStore at services/rook-ceph-cluster/1.10.3/defaults/cm.yaml#L126-L175 and override the replication strategy according to your needs by referring to CephObjectStore CRD documentation.
For more information about configuring storage in Rook Ceph, refer to the following pages:
Ceph OSD Management - Rook Ceph Documentation - for general information on how to configure Object Storage Daemons (OSDs).
Ceph Configuration - Rook Ceph Documentation - for information on how to set up auto-expansion of OSDs.
See Also: